
Meet Yash, an architect at CloudPinnacle Solutions, a company that provides high-quality consultants to clients facing tech challenges. With over a decade of experience as a consultant, Yash joined CloudPinnacle four years ago.

Recently, he completed a project and was waiting for his next assignment. One regular Monday, Yash was planning to leave the office early when he received a new email from his managers. His face lit up with a big smile while reading the mail and at the same time one of his managers approached him. Yash had been promoted to Lead Architect, which came not only with a salary increase but also additional responsibilities. Over the past four years, he had been working closely with Lead Architects, so he was well-acquainted with the role.
Atul, the manager, congratulated Yash and asked if he had 30 minutes to spare. Without a second thought, Yash agreed, and they both grabbed a coffee and headed to a meeting room. Atul proposed a new project with a new client for Yash to lead. This project was critical to the company, and Atul wondered if it would excite and challenge Yash.
Later that week, Yash was introduced to the client, PeakFlow Technologies. During the initial meeting, Yash met Raj, the tech lead for the project GreenGrid. Yash suggested an inception meeting with Raj and other tech stakeholders to understand the project and identify how CloudPinnacle Solutions could assist.
The inception meeting revealed that the GreenGrid project was facing difficulties due to lack of security, non-scalable infrastructure, and high AWS bills. After the inception, Yash began attending more meetings to understand their architecture and current infrastructure.
Yash recorded his thoughts with the following understanding:
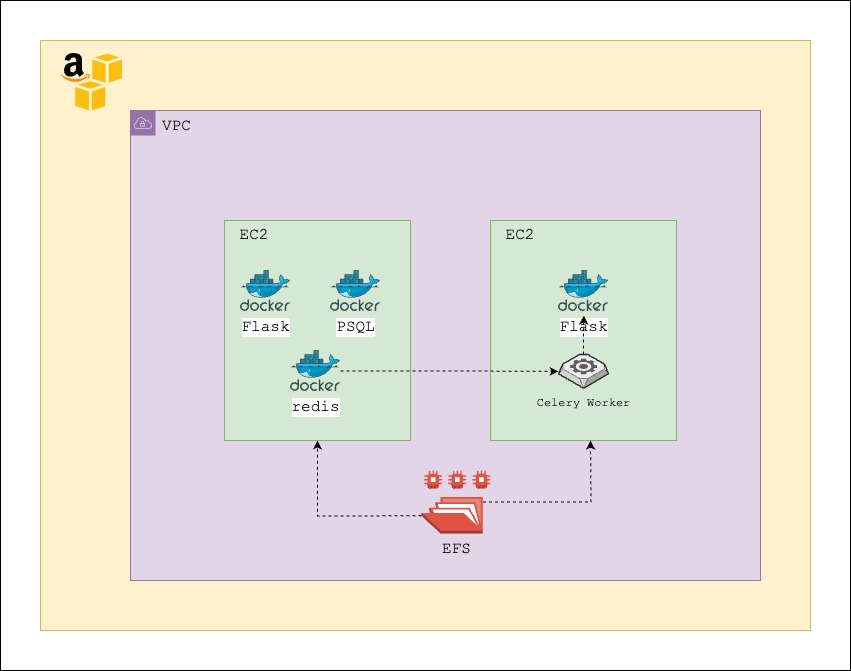
- The frontend is built using AngularJS and is a Single Page Application (SPA). It’s containerized using Docker and deployed on an EC2 instance with traffic routed via an nginx server.
- The frontend communicates with a backend built with Flask - Python, which uses a Postgres database. Both the Flask application and Postgres database are containerized using Docker and run on the same EC2 instance as the frontend.
- The Flask application also manages long-running compute jobs, triggered via APIs. These jobs require high computational power and are deployed on a separate, large EC2 instance due to their CPU and memory-intensive nature. The runtime for these jobs can vary from 10 minutes to 5 days, depending on the inputs provided.
- To facilitate communication between the two Flask services, a Redis Docker container is deployed on the first EC2 instance, acting as a queue. Celery, a Python library, retrieves jobs from the Redis queue and triggers a Flask API to run the job.
- Upon successful completion of the jobs, they write a CSV file to an EFS directory. This EFS is shared by both EC2 instances.
Yash added further notes on the problem statement:
- The entire EC2 was public, making the database publicly accessible on port 5432. This posed a significant security risk. The absence of firewalls made the system vulnerable to all possible attacks.
- Computational jobs were not running continuously, but depended on clients’ needs. There were days without any job running and some jobs required no more than 2 CPU cores. As jobs were triggered via Flask REST endpoints, parallel jobs were timing out because Flask could not process further requests. This posed a significant scalability issue.
- There was no straightforward monitoring system for the entire application. Developers had to log in to the EC2 instance and use the
tailcommand to view logs. - The team lacked an alerting system. There were instances where the application was down for more than 2 hours and the team was unaware of this until clients sent email notifications.
- There was no CI-CD pipeline. The entire deployment process was manual, requiring a developer to log in to the server, perform a git pull, docker build, and docker compose run, leading to application downtime.
- The heavy EC2 sizing resulted in a large AWS bill.
In the subsequent days, Yash discussed his infrastructure concerns with Raj. They found common ground, marking the beginning of potential collaboration between their companies. This progress prompted the client to agree to continue working on the infrastructure issue, much to Atul’s satisfaction.
Yash officially began work on this new project. From the start, he had an inkling of the solution for the application but was puzzled by the long-running jobs. To address this, he paired with the developers to learn more about these jobs.
Within a week, Yash discovered that these long-running jobs weren’t Python, as he initially thought, but were written in a different language called Julia. The Flask API was merely triggering Julia applications in a separate process. Consequently, Yash suggested isolating these Julia applications in their own Docker containers, explaining that their need for heavy computing resources made them unsuitable for Flask. With multiple Julia applications, multiple Docker containers could run simultaneously, potentially resolving the scalability issue. Although Raj and the team weren’t entirely convinced, their trust in Yash led them to further explore this solution.
However, Yash wasn’t entirely certain about the best platform for the long-running jobs. He initially thought of using an SQS, Lambda, and Fargate combination, replacing Redis with SQS and Celery with Lambda. His plan involved using ECS Fargate to spin up tasks on demand for these jobs. However, he was concerned about the overhead of managing a Queue and Lambda, which led him to seek advice from his seniors.
After explaining the problem to them, one suggested using AWS Batch to streamline the process by managing the queue, compute environment, and job execution. Yash quickly researched AWS Batch and conducted a small proof of concept. Satisfied with his findings, he proposed a new infrastructure plan to Raj and the team.
Here’s the solution proposed by Yash:
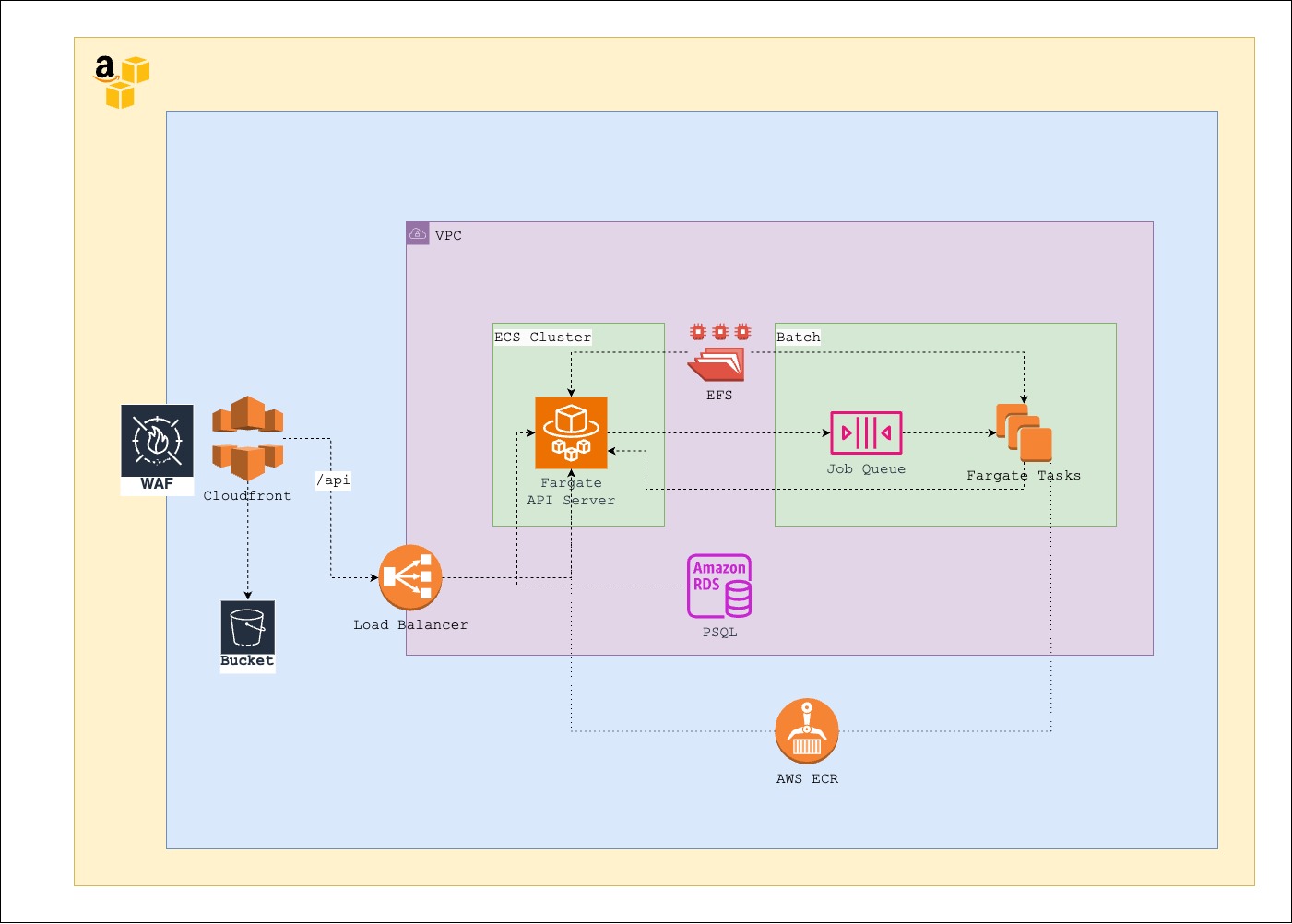
- Shift the frontend to AWS Cloudfront + S3. Given it’s a Single Page Application (SPA) with static assets, there’s no need to deploy it on a Docker container. Serving static files from a CDN will improve performance.
- Transition the database from Docker to an AWS managed service, specifically AWS RDS. This will enhance security as the database won’t be publicly accessible.
- Move the Flask container to ECS Fargate, providing scalability options for the API layer which will operate behind a load balancer.
- Segregate all Julia applications into separate Docker containers and deploy them to AWS Batch. This offers scalability for individual long-running jobs, enabling multiple jobs to run simultaneously. Additionally, it’s on-demand, meaning if no jobs are requested, nothing will run.
- Add an AWS WAF to Cloudfront for increased security.
As everything operates within a VPC, resources are not publicly accessible, and the application can only be accessed via a Cloudfront HTTP endpoint.
To start with this new infrastructure, Yash suggested using Infrastructure as Code (IAC) and introduced AWS CDK along with Github actions for a CI-CD pipeline. He commenced with Sprint 0, during which he paired with the team to write the initial CDK code. Each sprint targeted the delivery of one section of the new infrastructure.
Within just four sprints, the dev stage was successfully migrated to the new infrastructure. In the subsequent weeks, the team independently migrated the test and production stages. During this time, Yash stepped back to observe the team and allowed them to adapt to the new infrastructure.
Following this, Yash planned two additional sprints to set up application observability. Since the entire application was using AWS Cloudwatch, Yash utilized it to set up dashboards, monitoring, and a basic alerting system.
The entire migration process took roughly three months, and PeakFlow Technologies were pleased to see their application scaling and their AWS costs decreasing. Raj shared that the previous infrastructure bill was approximately 600 USD/month for a single stage. With the new infrastructure, the bill decreased by nearly 50%, to about 300 USD/month. Yash suggested further reducing these costs by reserving the RDS instances and converting the AWS Batch Fargate to spot instances. This spot conversion was only recommended for development and test stages.
AWS Fargate Spot instances offer a significant cost advantage because they allow you to take advantage of unused EC2 capacity in the AWS cloud. Spot instances are available at up to a 68% discount compared to On-Demand prices. Because Fargate abstracts away the underlying infrastructure, it can seamlessly use this spare capacity to run tasks without any intervention from you. However, these instances can be interrupted with two minutes of notice when AWS needs the capacity back. For this reason, they are ideal for fault-tolerant and flexible applications like data processing, batch jobs, or dev/test environments where an occasional interruption is acceptable.
PeakFlow Technologies invited Yash and several of his managers to a dinner party. Raj and other stakeholders from PeakFlow Technologies expressed their appreciation for Yash and CloudPinnacle Solutions for their assistance. Over dinner, they discussed upcoming engagement opportunities and requested additional developers to support their future endeavors.
The project’s success not only reduced client costs and improved their application’s performance, but also solidified Yash’s reputation as an innovative and competent Lead Architect. His initial major assignment in this new role gained him recognition within his company and the client’s trust for future collaborations. As we look forward to the next stage of Yash’s career, his journey stands as a testament to the power of innovation, strategic thinking, and unwavering commitment to excellence when facing technical challenges.
Disclaimer: This blog is a work of fiction, intended for illustrative purposes only. Names, characters, businesses, places, events, and incidents are either the products of the author’s imagination or used in a fictitious manner. Any resemblance to actual persons, living or dead, or actual events or companies is purely coincidental. The strategies and solutions discussed are generic and should be evaluated by professionals before considering them for real-world applications.