
The landscape of Artificial Intelligence (AI) has seen significant shifts and advancements with the release of transformative tools like ChatGPT. From Twitter to Reddit, discussions about AI, its applications, and varying perspectives on its implications are growing quickly. On the same note, at Travelopia, we’re harnessing the power of AI and integrating it into several areas of our operations. Tools like GitHub CoPilot and ChatGPT are increasingly being leveraged by our developers to boost efficiency – a move that is proving to be strategic and rewarding.

Recently, I had the unique opportunity to delve deeper into the intricacies of how AI works. As a web development professional, the concepts and terminologies of AI – such as LLMs, embeddings, tokens, vectorstores – were relatively unfamiliar to me. I decided to bridge this knowledge gap by building a project centered around AI.
The task I undertook was to create a chatbot trained on custom data. This training will be an extension to an already trained model. Since the purpose was to fine-tune an already trained model, it was necessary to use a model based on a transformer architecture, akin to GPT.
Understanding the training process was a crucial part of this endeavor. Here’s a brief breakdown of the process:
Data Gathering: Collect the text data that you want the model to learn from. This could be anything from a collection of books, scientific articles, website contents, etc.
Tokenization: Tokenize your corpus of data. This process involves breaking down the text into smaller pieces or “tokens”. Depending on your chosen method, these tokens could be words, subwords, or even single characters. For instance, a token could be “a”, “apple”, or even “app” if we’re using subword tokenization.
Embeddings: In the model’s training process, each unique token in the dataset is assigned a corresponding vector, or an “embedding”. The embeddings are high-dimensional vectors that represent the tokens in a way that captures their meanings and usages.
Text Generation: When a prompt is provided to the AI model, it generates a response by predicting the most likely next token, based on the prior tokens in the prompt. It uses the embeddings and the patterns it has learned during training to make these predictions. The model generates responses based on the patterns it has learned, without making any explicit reference back to the original training data.
For my ChatBot, I opted for NodeJS and LangChainJS.
I started off by executing the steps of Data Gathering and Tokenization. Using LangchainJS’s in-memory vectorstore, I was able to generate embeddings from the tokenized data.
const vectorStore = await MemoryVectorStore.fromTexts(
[
"Tears of the Kingdom takes place a number of years after Breath of the Wild, at the end of the Zelda timeline in the kingdom of Hyrule. Link and Zelda set out to explore a cavern beneath Hyrule Castle, from which gloom, a poisonous substance, has been seeping out and causing people to fall ill.",
],
{ series: "Zelda" },
new OpenAIEmbeddings()
);Subsequently, I needed to create a chain that piped the vectorstore embeddings to the LLM.
const llm = new OpenAIChat({});
const chain = MultiRetrievalQAChain.fromLLMAndRetrievers(llm, {
retrieverNames: ["zelda"],
retrieverDescriptions: ["Good for answering questions about Zelda Tears of the kingdom"],
retrievers: [vectorStore.asRetriever()],
retrievalQAChainOpts: {
returnSourceDocuments: true,
},
});I selected data from a game released in 2023 for training the bot. When I posed a question related to this game to ChatGPT, it responded thus:
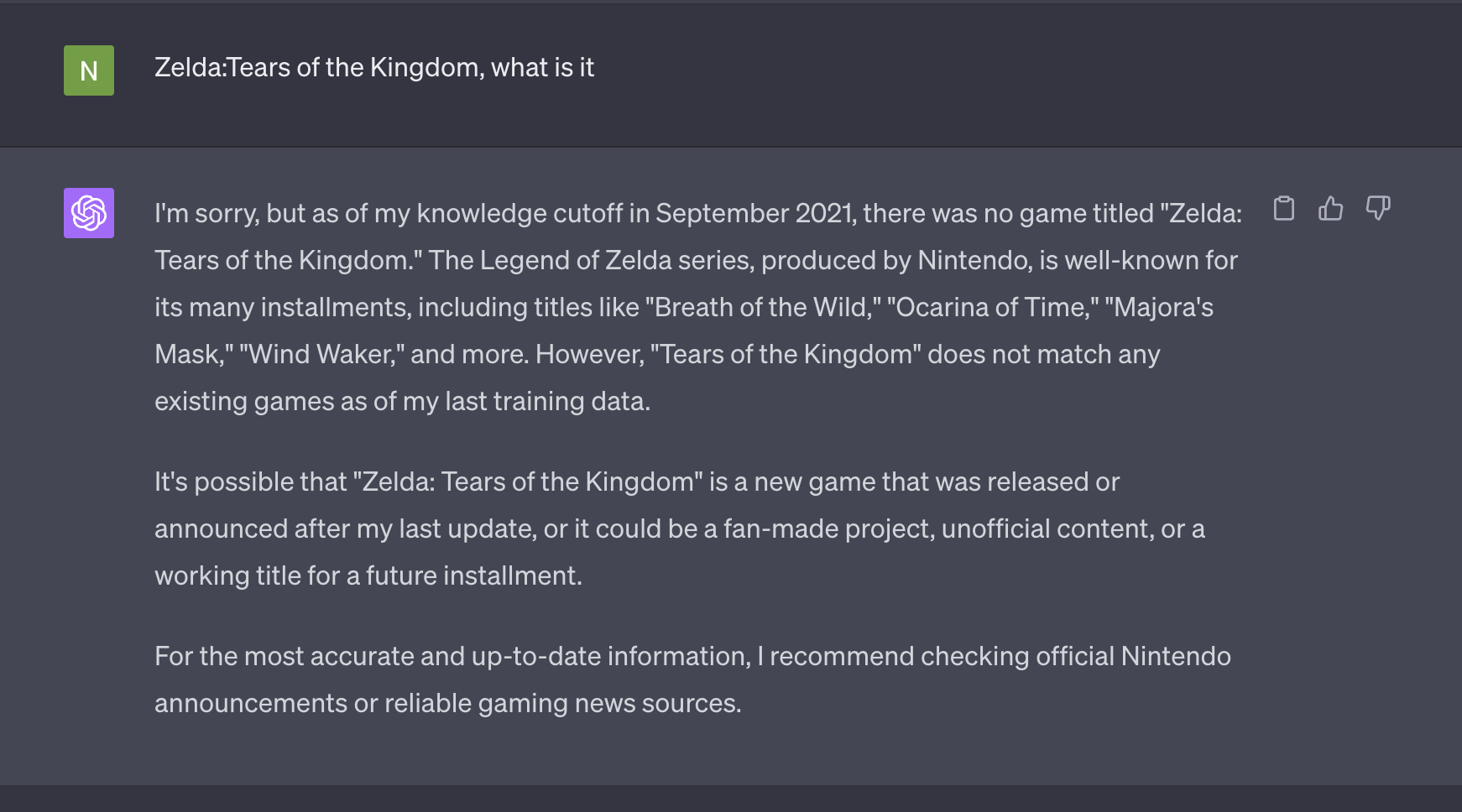
When I asked the same question to my bot, it responded:
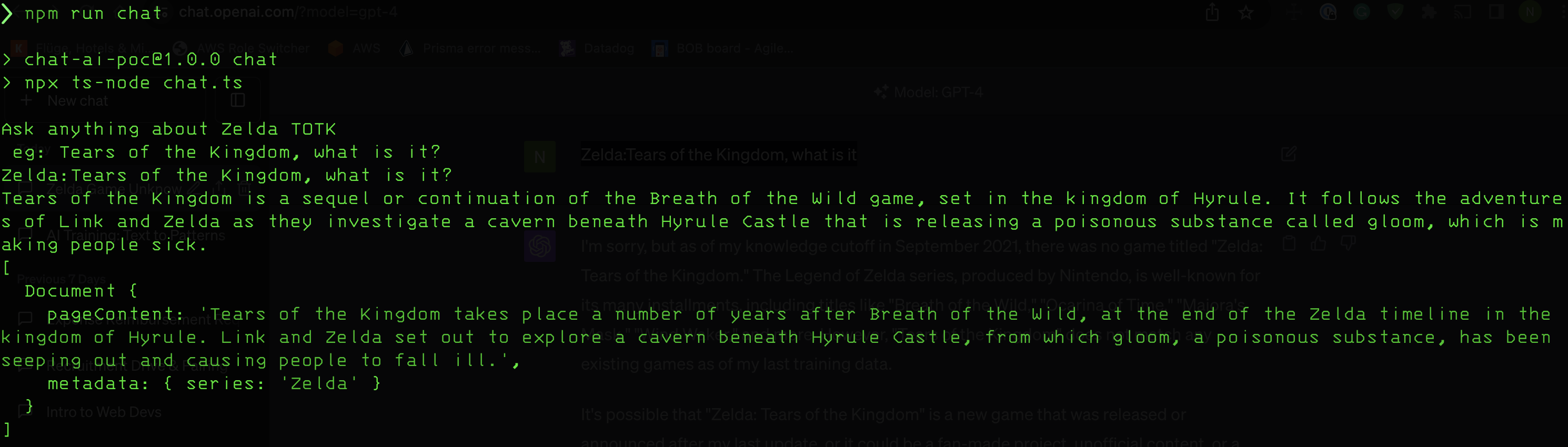
As depicted in the screenshot above, the bot successfully responded using information from the source document it was trained on.
You can access the code for this project on my GitHub repository.
Finishing this project made me appreciate OpenAI and GPT models even more. It also gave me many new ideas for using AI in future projects. This journey into AI has shown me the huge possibilities, especially when we can train models like GPT with our own data. This could change many different fields. I can’t wait to use these technologies more at Travelopia and find new ways to innovate. I’ll keep sharing my journey with you as I learn more about this exciting world of AI.